




生物过程开发中的机器学习:从承诺到实践(上)
发布时间:2023-09-20 16:41编者按
跟踪智慧实验室的理论研究发展状况、产业发展动态、主要设备供应商产品研发动态、国内外智慧实验室建设成果现状等信息内容。本文由中科院上海生命科学信息中心与曼森生物合作供稿。
本期推文编译了 Laura M. Helleckes 等发表在 Trends in Biotechnology 期刊上的综述论文《生物过程开发中的机器学习:从承诺到实践》(Machine learning in bioprocess development: from promise to practice),在此,作者展示了迄今为止 ML 方法是如何应用于生物工艺开发的,特别是在菌株工程和选择、生物工艺优化、放大、监测和控制生物工艺方面。对于每一个主题,作者重点介绍成功的应用案例、当前的挑战,并指出可能从技术转让和 ML领域的进一步进展中受益的领域。
就实际应用而言,机器学习(ML)已经成为人工智能(AI)中最重要的学科。ML 处理的是学习基于数据解决某些任务的算法和程序,其中性能随着经验 (即可用数据)的增加而增加。更准确地说,ML 旨在找到合适的、主要是经验模型来描述数据集,从标记的样本中学习或通过识别固有模式。当有大量数据可用时和/或当数据集过于复杂而无法通过预定义规则集进行分析时,大量的 ML 方法尤其有用。ML 的其他应用旨在寻找所谓的代理模型,其中 ML 模型被用作成本高昂或难以评估的机械模型的近似值。
近年来,生命科学已经开始研究可用的 ML 方法,研究人员开始评估其中哪些方法适合应对当前的挑战。因此,生物学和生物技术受到 ML 最新进展的影响。这反映在许多综述中,例如,ML 在蛋白质功能预测、多组学数据分析、发育生物学、生物网络分析、代谢工程和生物化学工程方面。
通常,从目标分子到最终产品的生物技术管道包括四个基本阶段:(1)目标鉴定和分子设计,(2)生物催化剂设计,(3)生物过程开发,(4)工业规 模生产。
其中,生物技术生产管道的第三阶段,即生物工艺开发,重点是通过菌株选择、工艺优化和扩大规模来提高目标分子的生产能力。在此阶段,通常进行高通量筛选 (HTS)实验来评估选定克隆的性能。此外,还需要从巨大的设计空间中确定最佳培养参数。然而,传统的分析方法,如质谱法,往往与实验速度不匹配,因此,分析随后成为瓶颈。
然而这一瓶颈可以通过使用 ML 根据样本的预测信息内容对样本进行排序并相应地安排其分析来解决,同时(高通量)平台已经可以执行进一步的实验。由于生物学和工艺参数是相关的,因此需要迭代实验和数据评估来反馈从筛选到菌株设计的信息和见解。这种方法反映在设计-建造-测试-学习(DBTL)周期中,该周期有时仅指合成生物学,但也可应用于生物过程开发阶段。在 DBTL 的背景下,所有步骤都可以通过 ML 进行增强,特别是为下一轮实验提供信息设计。
本文将从以下四个主要议题展开论述:
(1)菌株选择和工程
(2)生物工艺优化
(3)扩大生物工艺
(4)过程监控
01
PART
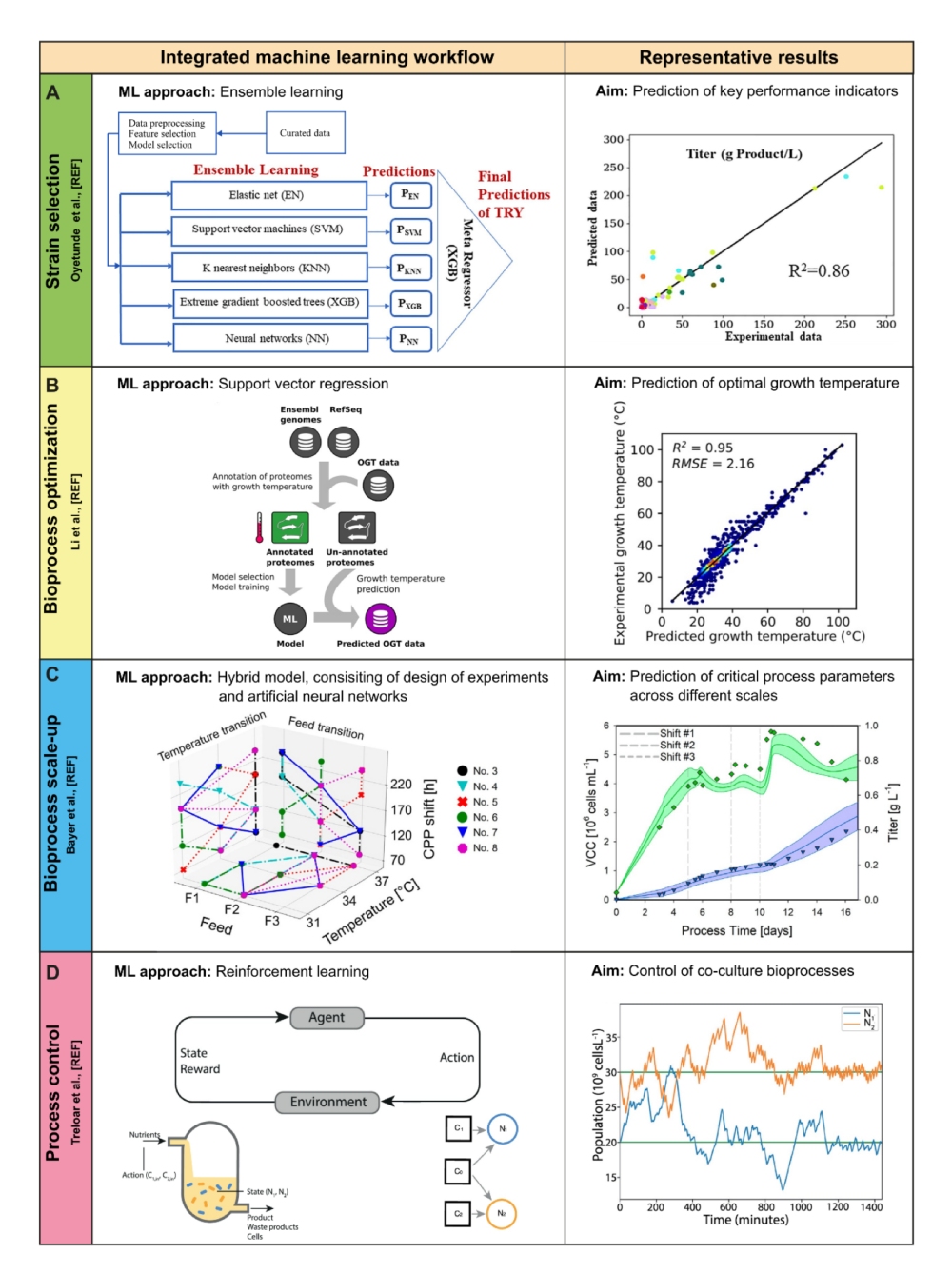
在众多候选菌株中进行选择:菌株工程和选择
生物工艺开发之前的一个核心步骤是选择用于生产的生物催化剂或微生物。HTS 的现有实验方法可以鉴定有效的生物催化剂(例如,通过菌株库的定量表型)。因此,当前的瓶颈是自动数据处理和算法驱动的决策,以选择具有最高商业生产潜力的生物催化剂。
ML 的最新进展提供了许多技术来促进菌株的生物化学工程。作为一个主要挑战,生物催化剂的多样性导致了一系列可能的任务,例如,设计和选择细菌生产菌株,预测不同无细胞系统中的生产,或工程哺乳动物细胞系。后者带来了许多额外的挑战,如克隆变异,需要进行大规模研究来产生机制理解,这是迄今为止非 ML 方法所需要的。
在过去的几十年里,化学计量和动力学基因组规模的模型已被用于代谢工程和生物过程开发。除了基因设计,这些模型还可以深入了解合适的碳源、培养基设计或生物反应器参数。多年来,已经使用基因组规模代谢网络的基于约束的建模(COBRA)对代谢工程进行了定量预测。COBRA 工具箱的方法,如通量平衡分析(FBA)、代谢调节最小化(MOMA)或最小割集(MCS),通常旨在优化生物网络(即代谢)中的通量,以通过例如减少副产物形成或消除竞争代谢途径来提高生产力。解析代谢途径并确定相应的通量是实验上的要求。因此,FBA 在很大程度上受到对底层网络结构的理解的限制。在 COBRA 工具箱中,FBA 可能是找到稳态通量解的最流行方法。
相反,数据驱动的 ML 算法允许分析大型、复杂(多)组学数据集,这些数据集可以以高吞吐量生成。ML 在基因组规模模型中的不同应用正在出现。一方面,ML 用于补充基于约束的模型的典型建模管道,即在基因注释、间隙填充和多组学数据整合的步骤中。另一方面,已经提出了新的混合建模方法,以及完全取代机制基因组规模模型的 ML 方法。
02
PART
提高和稳定 TRY:生物工艺优化
在生物工艺开发和优化过程中,实验室规模的生物工艺通过确定培养的最佳物理化学参数来提高 TRY。在这种情况下,使用了不同的 ML 技术。
针对微生物和酶在极端温度下的应用,Li 等人开发了一个支持向量机(SVM)回归模型,以最佳生长温度和氨基酸序列信息为输入特征, 预测酶活性的最佳温度。用于生物过程优化的另一种常见的 ML 方法是 GP 回归。使用案例包括优化藻类中的色素生产和调节谷氨酸棒杆菌中蛋白质生产的培养基组成。
最后,人工神经网络(Ann)经常应用于一系列应用(例如,优化小麦胚芽的培养基组成或蓝藻中的色素生产)。其他研究优化发酵参数;例如, Pappu 等人研究了温度、发酵时间、pH、kLa、生物量和甘油作为影响尼泊尔无核酵母中木糖醇生产的参数。Ebrahimpour 等人以生长温度、培养基体积、接种 物大小、搅拌速率、潜伏期和初始 pH 值为输入变量,优化了地杆菌菌株中热稳定脂肪酶的生产。最后,一些研究探讨了培养基组成和发酵参数的复杂相互作用 (例如,在用酿酒酵母生产生物乙醇或用于治疗的细胞系生长中)。
针对不同生物过程之间的知识转移,Rogers 等人通过转移学习模拟了不同生物体在生物化学过程中的动态行为,在这种情况下,通过部分保留不同 Ann 之间的层。Hutter 及其同事将 GP 回归与迁移学习相结合,更准确地说是嵌入向量,这是一种在自然语言处理中用于量化单词之间相似性的技术。这两种方法都显示了如何使用历史数据来预测新产品的动力学,这有利于生物工艺优化。
视频和图像数据(例如,细胞形态)是生物过程分析和控制的丰富信息来源。在这里,微流体系统与生命细胞成像相结合,开创了菌株 HTS 的图像分析方法, 并提高了对生物过程相关培养条件下细胞行为的理解。深度学习技术非常适合以自动化方式处理来自图像的如此复杂的原始数据,从而为微流体辅助的高通量生物过程开发奠定基础。最近的例子包括微流体单细胞培养和微流体液滴反应器中的生长和动力学预测,其中多层 Ann 用于预测流聚焦液滴发生器的性能。
工艺优化中的其他应用包括使用微观图像数据对生物膜进行时空分析和藻类培养。后者需要对光照条件和生长模式进行复杂的管理(例如,在培养过程中避免相互遮荫)。在这里,Long 等人使用 SVM 回归来预测显微镜图像中的光分布模式,这提供了对生长行为的深入了解,并可能最终有助于开发新的培养设计。
最后,看到了 ML 在化工自动化流程图合成中的进展,例如,分层强化学习和图神经网络已被成功应用。尽管尚未在生物工艺中得到证明,但这些技术在加速生物工艺发展方面具有巨大潜力。
未完待续
文章来源:https://www.sciencedirect.com/science/article/pii/S0167779922002815

相关文章
- 行业动态 |《上海市加快合成生物创新策源 打造高端生...2024-04-10 15:11
- 5万亿!大规模设备更新启动,生物智造企业接住这泼天富...2024-04-10 14:46
- 生物过程开发中的机器学习:从承诺到实践(下)2023-10-13 14:16
- 生物过程开发中的机器学习:从承诺到实践(上)2023-09-20 16:41
- 光酶催化不对称羰基羟基化反应2023-09-20 15:02
- 生物智造与智能装备专业委员会志愿者招募2023-09-13 13:17
- 生物智造与智能装备专业委员会志愿者/管理人员招募2023-08-29 09:57
- 2023年上海生物工程学会“曼森”生物工程 优秀青年...2023-08-16 08:37
- 国内外生物制造行业发展现状分析2023-06-30 15:09
- 德国2mag AG 公司的生物反应器2023-06-12 14:12

